

Ya no es raro para nadie escuchar hablar de Inteligencia Artificial Generativa, o lo que es lo mismo, de esos algoritmos que permiten generar imágenes de ti mismo de lo más artísticas —como os expliqué en el artículo de “cómo crear retratos de ti mismo con Inteligencia Artificial”—, que escriban textos bajo tus deseos, que generen vídeos o imágenes de lo más sorprendentes, con que sólo se lo pidas de una forma sencilla.

Un Chema Alonso hecho con IA al estilo Pixar.
Entender cómo funcionan estos algoritmos no es tan difícil, así que hoy voy a intentar explicaros cuál es el misterio de la creación en estos algoritmos que son capaces de hacer imágenes de las cosas que tú le pidas. Como veréis, no es magia, sino ciencia e innovación aplicada de la forma más inteligente, valga la redundancia, posible.
Dejadme que antes de empezar a explicar el misterio de la creación vaya hacia atrás un poco en la historia de la tecnología, cuando una década más o menos atrás comenzó la carrera para alcanzar la paridad humana en los llamados Servicios Cognitivos. El objetivo era sencillo: conseguir tener un algoritmo de IA que pudiera tener menos tasa de error que la media de los seres humanos en una determinada destreza cognitiva, como reconocer personas, reconocer el habla, reconocer objetos en una fotografía, traducir un texto, etcétera.
Si es una destreza cognitiva humana, entonces es objetivo de ser creado un servicio cognitivo basado en modelos de Inteligencia Artificial que alcance la paridad humana. Y así se ha estado estudiando y se sigue estudiando día a día. De todo esto os hablé largo y tendido en un artículo que publiqué por aquí llamado: “La IA que te mentía y la paridad humana”, que debes leerte si quieres profundizar y entender mejor cómo funcionan estos servicios cognitivos.
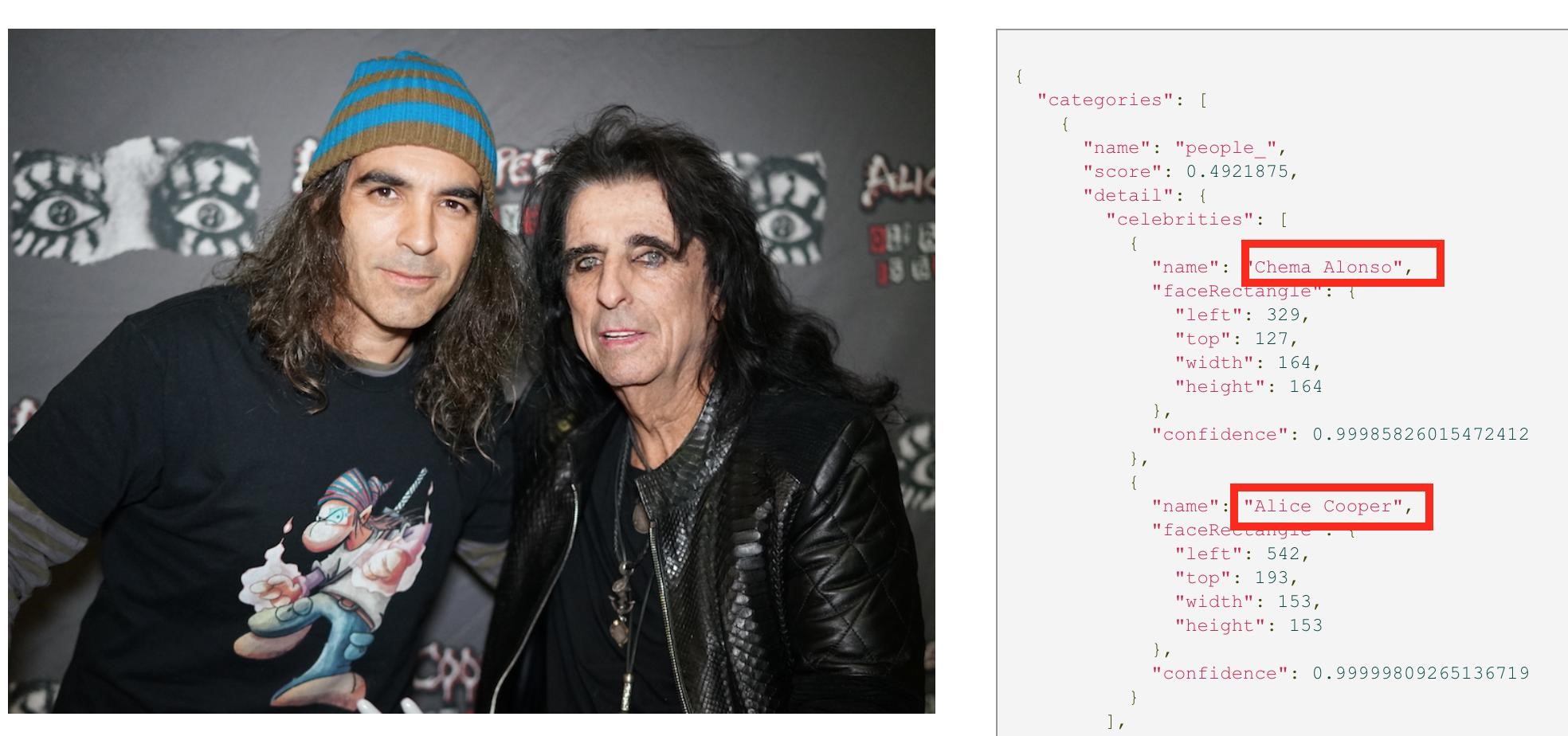
Reconocimiento de personas. Chema Alonso y Alice Cooper.
Dos de ellos, que van a ser fundamentales en la industria de las deepfakes o en la creación de retratos, son los cognitive services dedicados a reconocer personas, ya sean celebrities o no, como es el caso de esta foto con el gran Alice Cooper, donde nos reconoce perfectamente a ambos (y no nos confunde). Para la explicación de hoy del misterio de la creación, además del de reconocimiento de personas, vamos a utilizar el de reconocimiento de objetos y descripción de una imagen.
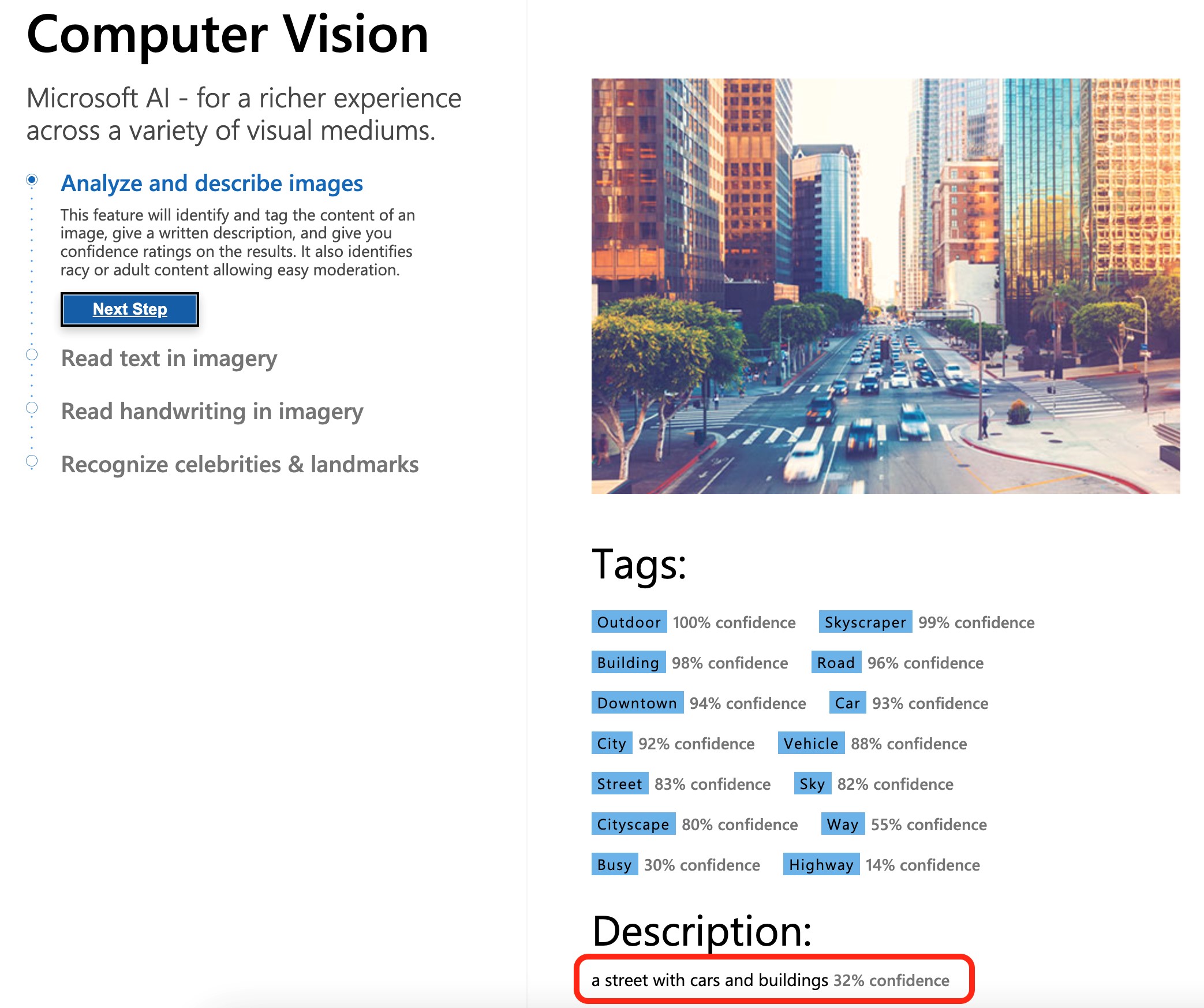
Microsoft Azure AI de Computer Vision.
Este servicio cognitivo es sencillo de entender. Se trata de darle una imagen, una fotografía, y el servicio cognitivo te devuelve la descripción de la fotografía. En este ejemplo podéis ver cómo funciona el servicio de Microsoft Azure AI de Computer Vision, donde es tan sencillo como darle una imagen, y obtener una descripción con un grado de confianza en la descripción.
Sencillo, ¿verdad? Tenemos un modelo de inteligencia artificial al que le damos una fotografía creada por un ser humano (inicialmente), y la inteligencia artificial es capaz de reconocer personas, cosas y describir la imagen. Le estamos enseñando cosas. Y cuando sepa mucho de esas cosas… será capaz de crear. Vamos a ver cómo.
Generative Adversarial Networks
Y aquí llega la magia. La magia del misterio. La magia del misterio de la creación que permite a una Inteligencia Artificial crear cosas que no existen. Crear imágenes de Chema Alonso totalmente nuevas. Crear una nueva imagen de cualquier persona que solo ha existido cuando la ha hecho el algoritmo de la GAN. Y la magia es tan sencilla como lo que se puede describir en este gráfico, que más vale que lo reviséis con cuidado, porque es la base de nuestra realidad.
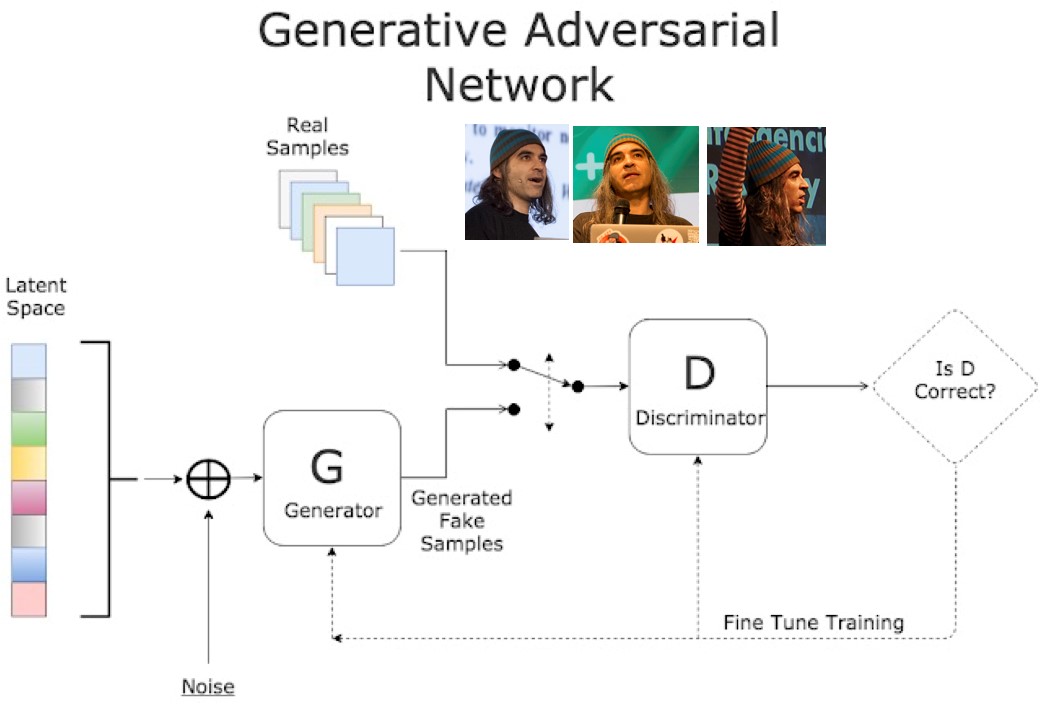
Descripción de una GAN.
El gráfico anterior tiene la explicación de todo lo que necesitamos saber para entender cómo es posible que una Inteligencia Artificial Generativa sea capaz de crear imágenes de cualquier cosa y de cualquier persona. Se trata solo de resolver esta ecuación de Generador – Discriminador. De enfrentar un algoritmo de generación de imágenes con un algoritmo de inteligencia artificial que utiliza un servicio cognitivo perfectamente entrenado.
Veréis: en el ejemplo anterior lo que tenemos es un cognitive service entrenado con datos reales, en este caso con fotografías de Chema Alonso, para que sea capaz de reconocer a Chema Alonso en cualquier imagen. Hoy en día basta con darle veinte o treinta fotografías —como hacemos en el caso del Servicio de Generación de Retratos de MyPublicInbox— de una persona, y nos quedaría un Discriminador capaz de reconocer a Chema Alonso en cualquier fotografía.
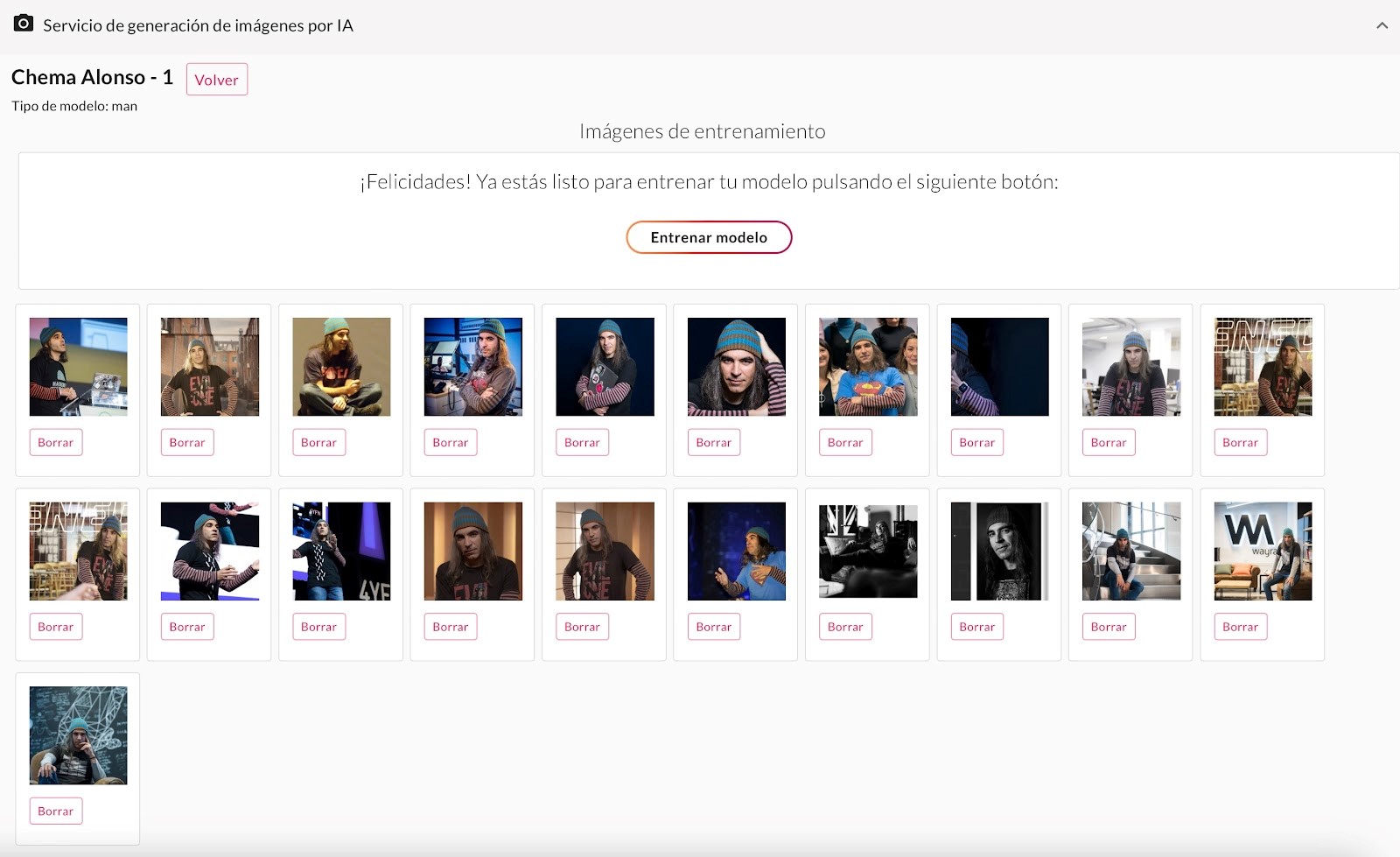
Imágenes utilizadas para entrenar a un discriminador para que me sepa reconocer en cualquier fotografía, en el servicio de retratos con IA de MyPublicInbox.
Y ya está. Se acabó. El resto es poner a pintar al Generador imágenes de Chema Alonso y ver si “convence” al Discriminador de que ha pintado a Chema Alonso. ¿Es esto posible? Pues claro que sí, pero según el algoritmo que utilice, será más rápido y de mejor calidad, o más lento y de peor calidad. Vamos a ver si me explico.
El algoritmo de los rotuladores Carioca
Supongamos que tenemos al Discriminador entrenado para reconocer a Chema Alonso, y ahora le damos una página en blanco y unos rotuladores Carioca al Generador, para que pinte a Chema Alonso. Cada vez que haga un intento, el Generador se lo pasa al Discriminador, y este le dice Sí o No con un grado de confianza. “La confianza en de que esta imagen sea Chema Alonso es del 0,0000000123%”. El Discriminador no dará como buena una imagen de Chema Alonso hasta que el grado de confianza supere un umbral, como del 95% o 98%. Dependiendo de la calidad que se quiera obtener.
Lo cierto es que con el algoritmo de la página en blanco y los rotuladores Carioca, el tiempo para resolver una imagen va a ser muy largo, y muy costoso. No pasa nada, estamos en el mundo del cloud computing, y tenemos cómputo infinito, pero el costo puede ser altísimo, lo que hace que no sea muy práctico. Pero… ¿y si buscamos algunos algoritmos para hacer que resolver el problema del Generador sea más rápido? ¿Y si le ponemos en el camino o le reducimos el problema?
Los algoritmos de las deepfakes
Existen muchos algoritmos para hacer deepfakes, pero dejadme que os cuente dos reducciones del problema que se utilizan para resolver el problema del generador. El primero de ellos es el de Lip Sync y el segundo es el de FaceSwapping. En ambos casos lo que se pretende es hacer una fotografía o un vídeo (fotograma a fotograma) para falsificar la imagen de una persona.
En el primero, el de Lip Sync, se usa para conseguir que una persona diga algo que no ha dicho y hacer la sincronización de los labios con las palabras, así que el generador lo único que tiene que tocar y pintar es la boca de la imagen. El ejemplo con Barack Obama es perfecto para entenderlo. Ahí se le construyó un audio cortando palabras de otras frases, y luego se usó un vídeo del presidente para pintarle fotograma a fotograma la forma de los labios.
En el segundo, el FaceSwapping, la idea es similar. No se pinta toda la imagen, solo partes de la cara, y para hacerlo más rápido y fácil, lo que se hace es contar con una corta-pega bruto en formato difuminado —lo que se llama el estado latente—. Dejadme que os lo explique, que es más fácil de lo que parece.
Supongamos que tenemos un vídeo de una persona A y le queremos poner la cara de la persona B. Para ello, cortamos los fotogramas donde sale la persona A. Seleccionamos la parte de la cara que queremos cambiar por la de otra persona y la difuminamos. Como si le pasáramos un difuminador de pintores. Luego buscamos imágenes de la persona B que tenga más o menos la misma posición de la cabeza y la cara. Cortamos la misma forma pero de la persona B y volvemos a difuminarla.
Una vez hecho esto, colocamos la cara difuminada de la persona B sobre la zona difuminada del fotograma del vídeo de la persona A, y listo. Lo siguiente es darle ese fotograma al Generador y decirle: “Haz una imagen de la persona B”. El Discriminador está preparado para reconocer a la persona B, y el Discriminador tiene que crear a la persona B, pero como parte de una imagen con solo la cara difuminada será un proceso mucho más rápido. Además, comienza con los colores cercanos a los que tiene que pintar, ya que está partiendo de los colores difuminados de la persona B. Y tardará mucho menos tiempo.
Chema Alonso haciendo FaceSwapping con la cara de Terminator.
Y esto es lo que hizo que el mundo de las deepfakes creciera y creciera y se hiciera cada vez más fácil falsificar a una persona o utilizarlo en la industria del cine. Pero aún podemos hacerlo más rápido, con un algoritmo mejor, basado en la idea de los colores difuminados en este algoritmo de FaceSwapping.
Los algoritmos de difusión
La llegada de los algoritmos de difusión ha sido el punto de inflexión en este mundo, ya que hemos creado una forma sencilla de permitir a una inteligencia artificial pintar al estilo en que lo hacen los seres humanos. Seguidme en el proceso, que veréis que no es tan difícil de entender.
Supongamos que yo te pido que pintes una playa de Andalucía. Y te doy una hoja en blanco y una caja de rotuladores Carioca, pero solo te dejo elegir diez rotuladores. ¿Los escogerías aleatoriamente? Seguro que no. Seguro que buscarías colores azules, algún blanco, colores tierra, etc… ¿Por qué? Pues porque tu cerebro tiene una imagen difuminada de esa playa. No es totalmente nítida esa imagen, no eres capaz de decir qué color hay en cada píxel en tu cabeza, pero sí que sabes que vas a necesitar esos colores, porque tu imagen mental tiene eso en la cabeza.
Pues generemos esa “memoria difuminada” a la Inteligencia Artificial. Démosle una base de datos de millones y millones de fotografías. Todas las que podamos. Y para que sepa qué hay en cada imagen utilicemos… tachán, tachán, tachán… un cognitive service que le describa los objetos y las personas de la fotografía, como el que hemos visto en la Figura 3. Así que tendremos por cada fotografía lo que hay en ella:
- “Una ciudad con coches y semáforos de noche”.
- “Un gato azul pintado en acuarela en estilo impresionista”
- “Un músico tocando la guitarra en un escenario”
- …
Perfecto. Ya hemos hecho la base de datos, pero… si le guardamos la base de datos con las imágenes completas, tendremos el problema de que si le pedimos después que nos haga algo, nos va a copiar exactamente lo que tiene almacenado. Así que hagamos magia y difuminemos la imagen con un algoritmo que “desordene ordenadamente” los píxeles de la fotografía, como podemos ver en la imagen siguiente:
Algoritmo de difusión.
Y esto es el misterio de la creación. Al final, lo que hace el algoritmo es guardar las imágenes difuminadas junto con su descripción, de tal manera que cuando alguien le pide a una Inteligencia Artificial Generativa que pinte “un gato azul sobre un libro rojo vestido de astronauta” no va partir de una hoja en blanco y rotuladores Carioca. No. En ese caso se irá a su base de datos y buscará imágenes difuminadas que estén cerca de lo que le han pedido: imágenes de gatos azules, de libros rojos, de trajes de astronauta, etc… pero todas están difuminadas. Eso sí, son desórdenes ordenados de la imagen. Como nuestra memoria. Como en el caso que os proponía yo con el dibujo de la playa.
Con esto conseguimos que el Generador comience a pintar con las imágenes superpuestas de las cosas que tiene que construir. Es como si tuvieras que hacer un Lego de un coche y te llevaras la caja con las piezas necesarias, pero desordenadas. Y no tan lejos de donde van, porque es un desorden ordenado. Como nuestra memoria, que recuerda cosas, aunque no sean exactas.
Así que el Generador parte de una imagen que está mucho más cerca del resultado que se busca que si comenzara de una página en blanco. ¿Y el Discriminador? Pues el Discriminador va a utilizar un servicio de descripción de la fotografía que le ha entregado el Generador para saber si ha cumplido o no con su objetivo. Es decir, cada vez que en Dall-e, Stable Diffusion o MidJourney la persona pide que se genere una imagen, ese prompt será lo que usará el Discriminador para saber si el Generador lo ha conseguido o no.
Y lo mejor es que cada vez que se genera una imagen esta pasa a formar parte de la base de datos de conocimiento. Se describe, se difumina y se amplía el conocimiento de estas Inteligencias Artificiales Generativas, haciendo que cada vez sean más rápidas y generen mejor. En la imagen siguiente se ve cómo para el mismo prompt en 2022 y un año después en MidJourney ha mejorado la calidad.

Evolución de MidJourney para el mismo prompt en 2022 y 2023.
Y cada vez que la usamos, cada vez que crea, se basa más en creaciones hechas por el algoritmo y menos en las creaciones originales. Porque hemos alimentado su base de datos validando las creaciones que ha ido haciendo.
Conclusiones finales
El mundo ya tiene a las Inteligencias Artificiales Generativas aquí, para hacer gráficos, vídeos, textos, y cada vez van a ser más reales, mejores, más rápidas, más exactas, y el mundo del cómic, los pósters, el cine, la creación audiovisual, serán su lugar más común de expansión. Como el Autotune, que llegó a la música para quedarse, sucederá lo mismo. Si te gusta este tema, te dejo mi charla sobre “Ciberseguridad y hacking en un mundo de Inteligencia Artificial, humanos y robots”, que habla de todo esto.
¿Copia o no copia la GenAI? Pues está claro que parte de imágenes creadas por humanos. Y si no entrenas bien el modelo —es decir, si lo entrenas con muy pocas imágenes—, salen los primeros diseños muy iguales a los originales humanos. Como si a un músico solo le enseñas canciones de Elvis Presley, sus primeras creaciones serán muy similares. Pero si le entrenas con canciones de muchos, muchos, muchos grupos, sus composiciones serán variaciones inspiradas en todo lo que han escuchado y… ¿no es así como creamos los humanos?



Zenda es un territorio de libros y amigos, al que te puedes sumar transitando por la web y con tus comentarios aquí o en el foro. Para participar en esta sección de comentarios es preciso estar registrado. Normas: